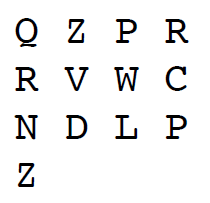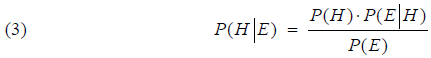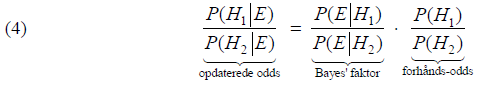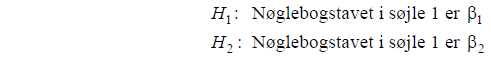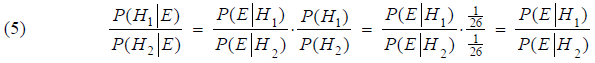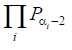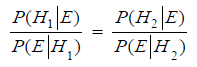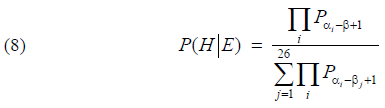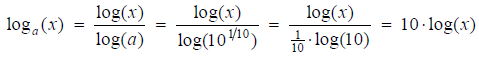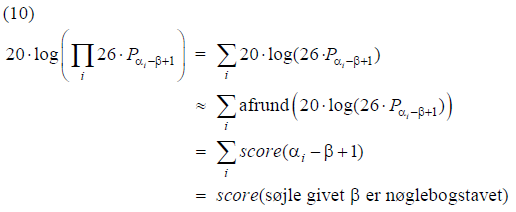|
Turings angreb på Vigenère chifferetPå Enigma-siden blev det omtalt, hvordan man i Bletchley Park benyttede statistiske metoder til at hjælpe med at bryde flådens Enigma M3. Grundet den ret komplekse teori bag og også den lidt komplicerede praktiske procedure bag Banburismus, måtte jeg imidlertid afstå fra at give udførlige detaljer. På dette sted vil jeg imidlertid vise, hvordan man kan anvende Bayes' formel til at knække et mere simpelt chiffer, nemlig det såkaldte Vigenère chiffer. Denne proces blev faktisk beskrevet af ingen ringere end Alan Turing selv! I 2012 frigav det britiske efterretningsvæsen nemlig en forskningsartikel skrevet af Alan Turing under krigen: The Application of Probability to Cryptography (se [1]). Heri beskriver Alan Turing, hvordan statistiske metoder kan benyttes i fire forskellige situationer: Vigenère chifferet, A letter subtractor problem, Theory of repeats samt Transposition ciphers.
1. Statistikken anvendt i kryptologi historiskDet er velkendt, at de første substitutionscifre, hvor et bogstav blot udskiftes med et andet, kunne knækkes ved at benytte simpel statistik: Er den krypterede tekst lang nok, kan man normalt regne med, at det bogstav, der forekommer oftest, er et E i klartekst, etc. Med det mere avancerede Vigenère chiffer blev det sværere, fordi bogstavfrekvenserne glattes ud. Alligevel lykkedes det Kasiski og Friedman at opfinde en procedure, der kunne hjælpe ti med at knække Vigenére chifferet - hvis den krypterede tekst vel at mærke er lang nok, så man kan konkludere noget signifikant af statistikken. Den interesserede læser kan læse mere herom i [5]. Disse metoder bygger alle på, at frekvenserne af de forskellige bogstaver i en almindelig klartekst, er forskellige. Hvis bogstavfrekvenserne alle havde været ens, ville alle metoderne falde til jorden. Det samme er tilfældet med Alan Turings statistiske metoder. Forskellen er bare, at Alan Turing hiver endnu mere information ud af det tilstedeværende data eller evidens (i form af den krypterede tekst), hvorved metoden bliver endnu stærkere.
2. Vigenère chifferet kortVi skal ganske kort se på Vigenère chifferet her. Der er tale om et polyalfabetisk system, forstået derved, at man anvender flere forskellige alfabeter (substitutioner), hvilket betyder, at et bogstav kan krypteres til flere forskellige bogstaver forskellige steder i teksten. I Vigenère chifferet gør man brug af en hemmelig nøgle. Lad os se på et eksempel. Udgangspunktet er følgende tabel (Klik evt. for en større udgave):
Lad os sige, at vores hemmelige nøgle er POLY, og at vi ønsker at kryptere klarteksten BLETCHLEYPARK. Da tager man første bogstav i klarteksten, som er et B og første bogstav i nøglen, som er et P. Ud for B i øverste række og P i venstre søjle ser vi bogstavet Q. B krypteres altså til et Q. Næste bogstav i klarteksten er L, og det næste bogstav i nøglen er O. Ud for L i øverste række og O i venstre søjle, ser vi bogstavet Z. L dekrypteres altså til Z. Sådan fortsættes: E krypteres til P og T dekrypteres
til R. Nu er vi kommet til enden af nøglen og begynder forfra: Ud for C i øverste række og P i venstre række ser vi bogstavet R. Altså dekrypteres C til R. Vi fortsætter på denne måde og ender med at klarteksten BLETCHLEYPARK dekrypteres til QZPRRVWCNDLPZ. Nedenfor er vist de aktuelle aflæsninger markeret med rødt:
Vi kan arrangere den krypterede tekst i rækker af 4 bogstaver, svarende til længden af nøgleordet POLY. Fordelen ved det er, at så ved vi, at alle bogstaver i samme søjle er krypteret med det samme bogstav i nøglen, og dermed er krypteret med det samme alfabet!
Dermed er man tilbage i et simpelt monoalfabetisk krypteringssystem, hvor man nemt kan knække koden - hvis bare man har en lang nok tekst. Det er selvfølgelig ikke tilfældet her. Der er maksimalt fire bogstaver at udføre statistik på! Et andet problem er i øvrigt at bestemme nøglelængden (nøgleordet er jo hemmeligt), så man kan ikke sætte den krypterede tekst op som ovenfor uden denne viden. Her var det imidlertid at Kasiski og især Friedman, som præsenterede en statistisk metode til at give et godt bud på nøglelængden. Den interesserede læser kan læse mere herom i [5].
3. Alan Turings eksempelI artiklen The Application of Probability to Cryptography (se [1]) kigger Alan Turing på følgende krypterede tekst: DKQHSHZMNPRCVXUHTEAQXHPUEPPSBKTWUJAGDYOJTHWCY-DZHGAPZKOXOEYAEBOKBUBPIKRWWACEJPHLPTUZYFHLRYC som er delt tilfældigt i to dele med et -, da teksten ikke kan stå på en linje. Vigenére chifferet er anvendt til at kryptere. I de følgende afsnit skal vi se, hvordan først Friedman-testen med simpel statistik og derefter Alan Turings metode klarer opgaven med at dekryptere kryptoteksten. For en ordens skyld anbringer vi på dette sted den tilhørende klartekst samt den hemmelige nøgle. Men i det følgende skal den altså anses som ukendt! Hemmelig nøgle: POIUMOLQNY Klartekst: OWINGTOWARCONDITIONSITHASBECOMEIMPOSSIBLETOIMPORT-CALCULATINGMACHINESXTHISISVERYREGRETTABLE
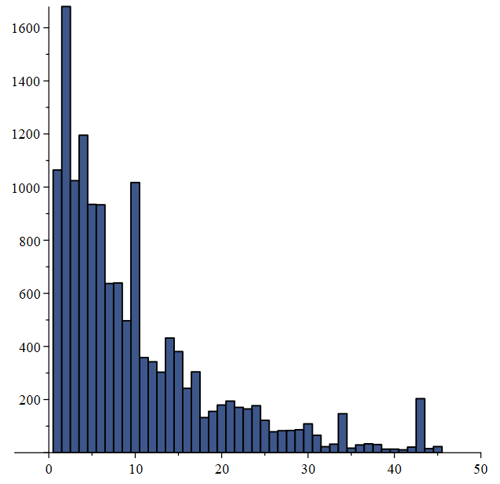
4. Friedman testen og simpel statistik anvendtNedenfor angiver vi resultatet af at anvende Friedmans test på Alan Turings eksempel fra afsnit 3. Den interesserede læser henvises til [5] for en forklaring på, hvordan Friedmans test virker.
Histogrammet antyder at 10 er et godt bud på nøglelængden, da søjlen ud for 10 på førsteaksen er specielt høj. Man kunne også overveje om 2 kunne være nøglelængden. Vi går imidlertid med de 10 i det følgende. Som omtalt i afsnit 2 er det nu hensigtsmæssigt at organisere den krypterede tekst i rækker af 10 bogstaver, svarende til at nøglelængden er 10. :
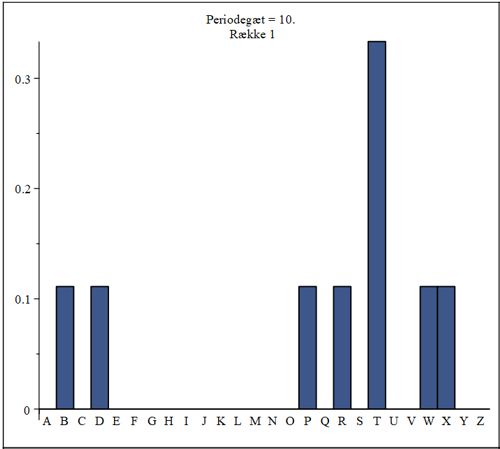
Bogstaverne i hver af de 10 søjler er altså krypteret med det samme alfabet (substitution)! Vi kender dog stadig ikke nøgleordet (kun dets længde) og kan derfor ikke umiddelbart sige, hvilke alfabeter, der er anvendt. Vi vil nu forsøge at udføre statistik på hver enkelt søjle. Lad os se på den første søjle. Uden detaljer får vi følgende histogram:
Vi ser, at statistikken er dårlig. Der er for få bogstaver i hver søjle. Histogrammet foreslår indirekte T til at svare til et E i klartekst, da denne søjle er højest. Hvis vi kikker i Vigenére tabellen, ser vi, at hvis nøglebogstavet er P, vil E netop kryptere til T. Her ramte den simple statistik altså rigtig, da vi bagklogt ved, at det første bogstav i nøgleordet netop er et P. Lad os se på søjle 2:
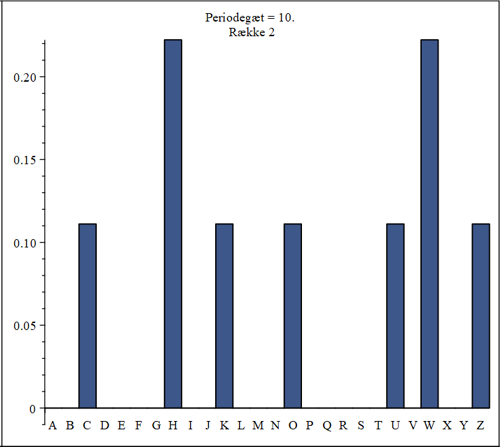
De højeste søjler er her H og W. Vi ved bagklogt, at det rigtige 2. nøglebogstav er et O, så søjlen S skulle have været høj, hvis histogrammet korrekt skulle udpege et E i klartekst. Men S søjlen er faktisk helt tom. Vi kunne fortsætte på denne måde med de øvrige 8 søjler. Det viser sig, at kun i to af disse søjler udpeger den højeste søjle det bogstav, som skal være krypteringen af et E. Metoden er altså ikke helt god, når der er så korte kryptotekster. Man må i så fald i hvert fald komme med gæt og foretage diverse afprøvninger for at se, om man kan få noget meningsfuld klartekst ud af det.
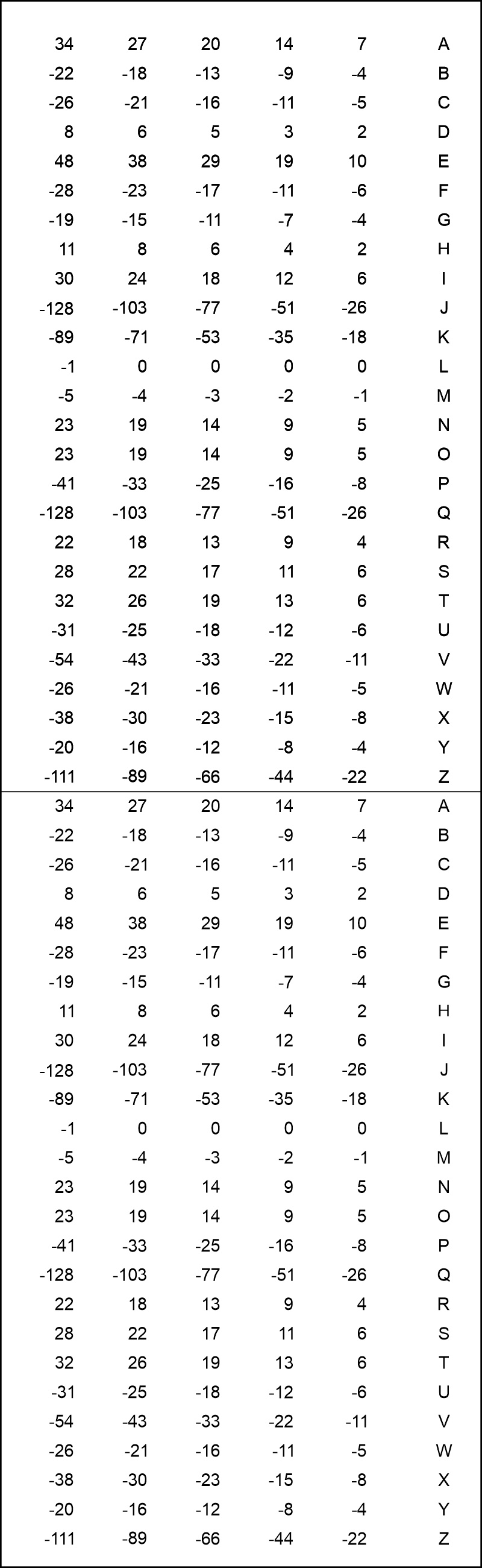
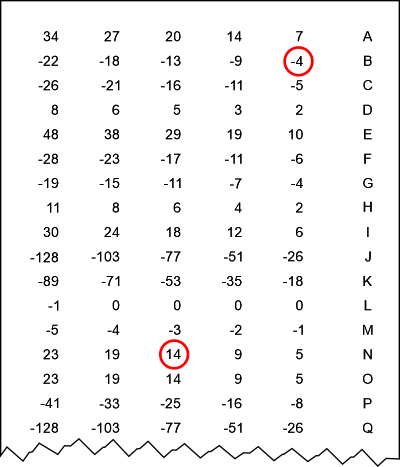
5. Alan Turings statistiske metode anvendtVi skal i dette afsnit se, hvor godt Alan Turings statistiske metode klarer opgaven. Vi vil dog antage, at vi på forhånd har benyttet Friedman testen til at give en vurdering af nøglelængden, altså at den er 10. Nedenfor skal vi anvende metoden uden teoretiske forklaringer. Dem udskyder vi til senere afsnit. Vi får brug for en "scoretabel" (klik evt. for en større udgave):
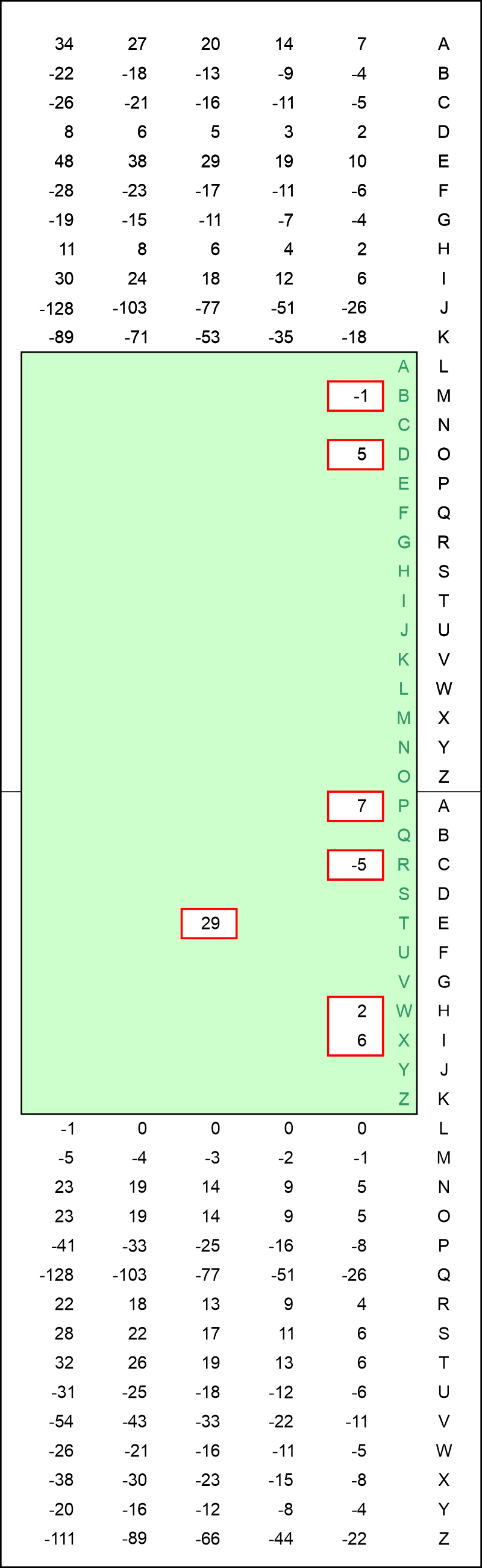
Hvorfor den ser ud, som den gør, gemmer vi altså til senere. Enheden for tallene i tabellen er halve deciban, hvilket defineres i afsnit 8. Vi kigger nu på bogstaverne i første søjle i den røde "matrix" i forrige afsnit: DRXTTPBWT. Der er ét stk. af følgende bogstaver: D, R, X, P, B, W. Derudover forekommer bogstavet T i alt tre gange. Vi udfærdiger nu en "skyder", hvori vi har lavet huller ud for de nævnte bogstaver. Forekommer bogstavet kun én gang,
skal hullet være over talkolonnen længst mod højre. Forekommer bogstavet to gange, skal hullet anbriges over tallene i den talkolonne, der er næstlængst mod højre. Forekommer et bogstav tre gange, anbringes hullet over den talkolonne, der befinder sig tredjelængst mod højre, etc. I det aktuelle tilfælde er den korrekte skyder vist på figuren nedenfor (klik evt. for en større udgave).
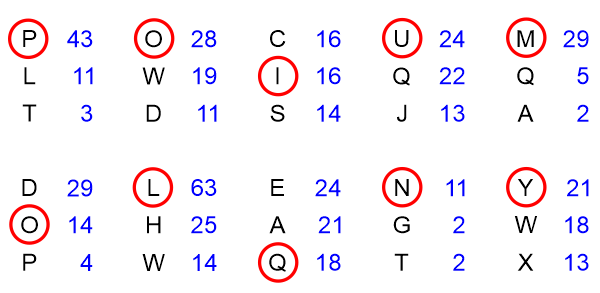
Meningen er nu, at man kan forskyde den grønne skyder op og ned, indtil summen af de tal, som kan ses gennem hullerne i skyderen er størst mulig! Figuren viser det tilfælde, hvor den største sum fås: 43 halve decibans. Dermed er det bogstav, der står ud for A i den yderste højre kolonne med bogstaver, et godt bud på nøglebogstavet i 1. position. Vi ser, at det giver et P, hvilket vi bagklogt ved er rigtigt. Man kan udføre samme procedure for hver søjle - med en ny skyder for hver søjle!. Derved fås følgende, hvor vi har opskrevet de tre bogstaver (og bud på nøglebogstaver), som giver de største scorer (i halve deciban) - dem med højst score øverst.
Vi ser, at i 7 af søjlerne fås de korrekte nøglebogstaver som de bogstaver, der har den højeste score. I to tilfælde er det rigtige nøglebogstav det med næststørst score, og i et enkelt tilfælde er det rigtige nøjlebogstav det med tredje størst score. Værdierne for scorerne står til højre for med blå farve. Værdierne er ikke så forskellige for de tre øverste. Havde teksten blot været en smule længere, ville man i mange tilfælde have set, at den øverste værdi skiller sig klart ud, ofte med negative scorer allerede i position 2. Under alle omstændigheder ser vi at resultatet er væsentligt bedre end det, som den simple statistik fra forrige afsnit gav. Årsagen er, at Alan Turings metode trækker meget mere information ud af den data eller evidens, som er tilstede - i form af den krypterede tekst! Vi skal se på metodens teoretiske grundlag i de næste afsnit. Har man den hemmelige nøgle, kan man nemt bestemme klarteksten. Der vil stadig være behov for nogle afprøvninger, men klart færre end tilfældet er, hvis vi anvendte den simple statistik fra afsnit 4. Den opmærksomme læser har måske undret sig over, hvorfor score-værdierne fra A til Z er gentaget lodret over hinanden. Det er gjort af praktiske årsager, så skyderen blot kan forskydes nedad, når man har behov for at starte forfra i alfabetet ... NB! Det skal nævnes, at der er små ubetydelige afvigelser i den scoretabel, som jeg selv har udregnet ovenfor og så den scoretabel, som findes på figur 3 i Alan Turings artikel [1] side 7. Måske Alan Turing foretog nogle små afrundinger undervejs i det ret store manuelle arbejde med at bestemme scorer? Afvigelserne har dog ikke nogen stor praktisk betydning.
6. Bayes' formel på relative odds formSom nævnt bygger Alan Turings statistiske metoder på Bayes’ formel. I det følgende skal vi se, hvordan den kommer i spil. Jeg vil være lidt kortfattet i den første del, hvor det handler om alment kendte relationer. Den interesserede læser, som ønsker uddybning, kan se kapitel 4 og 5 i min note [4]. Lad H og E være to hændelser i et endeligt sandsynlighedsfelt, hvor P(E) er forskellig fra 0. Den betingede sandsynlighed for H givet E er da defineret ved:
Symmetrien giver dermed umiddelbart:
hvormed den simple udgave af Bayes’ formel fremkommer:
Den dybere mening med Bayes’ formel er, at den kan bruges til at vende rundt på hændelserne i betingede sandsynligheder. Har vi to hændelser (hypoteser) H1 og H2, kan vi bruge Bayes’ formel (3) på hver af dem for den samme evidens E, hvorved man umiddelbart får følgende relation, som kaldes Bayes’ formel på relative odds form:
Den såkaldte Bayes’ faktor er forholdet mellem sandsynlighederne for at se den konkrete evidens E givet henholdsvis hypotese H1 og hypotese H2. Indholdet af (4) kan tolkes derved, at man har givet nogle forhånds-odds for to hypoteser H1 og H2 og sat hypoteserne op mod hinanden. Ved at gange med Bayes’ faktoren, får man de opdaterede odds (posterior odds), efter den konkrete evidens er taget i betragtning. Bayes’ faktoren kaldes også undertiden for Likelihood-kvotienten.
7. Bayes' anvendt på det aktuelle problemVi vil nu bruge teknikken på det tilfælde, hvor evidensen E er den, som fremgår af de krypterede bogstaver i første søjle i den røde "matrix" i afsnit 4. Det er vores data eller evidens. Som de to hypoteser, ser vi på følgende:
hvor β1 og β2 er to givne bogstaver. Formel (4) ovenfra giver her:
Vi har her brugt, at vi kan antage, at det er lige sandsynligt hvilket nøglebogstav, der er valgt i 1. søjle, hvorfor forhånds-odds bliver (1/26)/(1/26) = 1. Nøglebogstaver kan nemlig vælges helt frit, og nøgleordet behøver ikke at give nogen mening, altså være et egentligt ord i det engelske sprog. Indholdet af (5) er dermed, at de opdaterede odds – efter der er taget højde for evidensen E (data i 1. søjle) – kan udregnes ved Bayes-faktoren vist på højre side i (5). Tælleren i Bayes-faktoren kan tolkes som sandsynligheden for at få søjle 1 givet at nøglebogstavet er β1. Tilsvarende med nævneren. Lad os i det følgende udregne et udtryk for den betingede sandsynlighed i tælleren. Lad os for det første betegne rækken af krypterede bogstaver i søjle 1 med α1, α2, ... , αi, ... I det aktuelle tilfælde svarer det til følgen D, R, X, T, T, P, B, W, T. Lad os et øjeblik antage, at nøglebogstavet hørende til 1. søjle i den røde "matrix" i afsnit 4 er et C. Da ved vi, at klarteksten fås ved at skifte baglæns med 2: D er krypteringen af B, R er krypteringen af P, etc. Den antagede klartekst hørende til 1. søjle er nedenfor farvet blå:
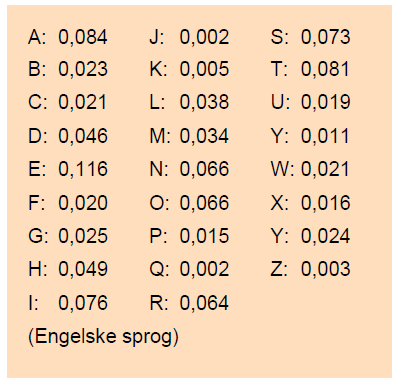
Spørgsmålet er nu, hvad sandsynligheden er for at få søjle 1, hvis nøglebogstavet er et C? Her kan vi udnytte, at vi er tilbage i klartekst, for der kender vi bogstavfrekvenserne. Alan Turing anvendte følgende værdier for bogstavfrekvenserne for det engelske sprog:
Vi kan med god tilnærmelse gå ud fra, at hændelserne at få hver af de ni bogstaver i den blå 1. søjle er uafhængige hændelser, da der er 10 skridt imellem dem i den engelske tekst. Det betyder, at sandsynligheden for at få dem alle, er produktet af deres frekvenser. Idet vi kalder frekvensen af det k'te bogstav for Pk, angiver følgende produkt sandsynligheden for at få første søjle, hvis nøglebogstavet er C:
hvor vi identificerer bogstaver med tal på følgende måde: A med 1, B med 2, ... , Z med 26. For eksempel er α1 her lig med D, som vi identificerer med 4. Trækkes 2 fra, fås 2, som svarer til B i klartekst. Så den første faktor i produktet er altså frekvensen af klarbogstavet B, og den er ifølge Alan Turings frekvenstabel lig med 0,0023. Tilsvarende med de øvrige faktorer i produktet. MEN nu behøver nøglebogstavet i søjle 1 jo ikke at være et C. Vi kender det jo ikke. Det er faktisk det bogstav, som vi ønsker at bestemme! Hvis vi kalder det pågældende bogstav for β, så angiver følgende produkt sandsynligheden for at få første søjle, hvis nøglebogstavet er β (overvej):
hvor det er underforstået, at E er evidensen i form af 1. søjle af kryptoteksten og H er hypotesen at nøglebogstavet for søjlen er β. Det vil være oplagt at tage udgangspunkt i sandsynligheden P(H|E), når vi i næste afsnit skal udfærdige scoringstabellen fra afsnit 5. Jo større den betingede sandsynlighed er, jo mere sandsynligt er det, at nøglebogstavet β er anvendt. Identiteten (5) ovenfor viser imidlertid, at vi lige så godt kan vende rundt på hændelserne i den betingede sandsynlighed. Sandsynlighederne P(E|Hi) er nemlig proportionale med sandsynlighederne P(Hi|E), som følgende omskrivning af (5) viser:
Vi kan altså i første omgang bruge udtrykket på højre side i (6) - eller noget, som er proportionalt med det - i vores arbejde med at konstruere en scoretabel. Alan Turing valgte af praktiske grunde at gange 26 på, dvs. han anvendte følgende udtryk som udgangspunkt til at beregne scoren:
BemærkningI artiklen [1] angiver Alan Turing desuden, at sandsynligheden for, at det rigtige nøglebogstav er β, givet evidensen om første søjle, er lig med følgende udtryk:
hvor man har divideret med summen af sandsynlighederne for at se søjlen givet hvert muligt nøglebogstav. Formlen fås af Bayes' formel og kendsgerningen at forhånds-sandsynlighederne alle er 1/26. Formlen er dog unødvendig og bringer argumenterne ovenfor lidt på afveje ..., dvs. formlen er unødvendig her. (6) er blot tælleren i (8).
8. Deciban og scoretabelAlan Turing indså, at det ville være regnetungt at skulle foretage multiplikationerne i udtrykket (7) manuelt. Inspireret af måden, man definerer lydtryk på i fysik ved hjælp af en logaritme, bestemte Alan Turing sig for at scoren for et bogstav i alfabetet skulle være logaritmen til 26 ganget med bogstavfrekvensen. Vel at mærke logaritmen med grundtallet a = 101/10. Fordelen ved at bruge logaritmer er, at man laver multiplikation om til addition, hvilket sparer rigtig meget tid, når man skal håndtere scorerne manuelt. Da alle logaritmer er proportionale, kan vi oversætte til den velkendte titalslogaritme log(x) :
Enheden blev benævnt deciban (i stil med decibel). Her var ban inspireret af Banbury, som tidligere omtalt. Imidlertid kom en af Turings kolleger, I. J. Good, med et forslag om at regne i enheden halve decibans, fordi det ville lette regnearbejdet en del. Scoren regnet i halve deciban for det k'te bogstav Pk skulle dermed være:
Lad os se på et par eksempler. Først udregner vi scoren for det 2. bogstav i alfabetet, altså et B:
hvor vi finder 0,023 som frekvensen af B i frekvenstabellen ovenfor. Bemærk, at der blev afrundet til nærmeste hele tal, så man ikke skulle bekymre sig om kommatal. Det var rigeligt nøjagtigt i praksis. Hvis et bogstav forekom flere gange i en søjle, kunne man selvfølgelig gange bogstavets score med det antal gange det forekom, men det var mere hensigtsmæssigt at udregne direkte, hvad det gav i samlet score (det blev også mere nøjagtigt på grund af afrundingen!). Lad os for eksempel antage, at det 14. bogstav, som er et N, forekommer 3 gange i søjlen. Da ville det give en samlet score på 14:
Vi ganger altså bare med 3 udenfor logaritmen og afrunder. En samlet score på 14 for de tre N'er. Scoren blev anbragt i den tredje talkolonne, regnet fra højre, i scoretabellen (se afsnit 5).
Ved hjælp af (7) kan vi udregne den samlede score (op til afrunding) i en søjle, hvis nøglebogstavet er β:
hvor et bogstav identificeres med dets nummer i alfabetet. Det overlades til læseren at overbevise sig om, at den i afsnit 5 omtalte teknik med en skyder i scoretabellen, netop svarer til at foretage beregningen i (10) - dog underforstået at man skal udregne scorer for bogstaver, der forekommer flere gange i søjlen, på én gang, som vist med eksemplet 3 styk N ovenfor.
9. Theory of RepeatsAlan Turings tredje eksempel på anvendelse af sine statistiske metoder i artiklen [1] er beskrevet i hans afsnit Theory of Repeats. Det er nok dette afsnit, som kommer tættest på det, man anvendte i praksis i Bletchley Park. Det handler om at sætte to dokumenter "in depth", vurderet ud fra gentagne bogstaver (repeats), bigrammer, trigrammer, etc. Det er forholdsvist kompliceret, og der mangler scoretabeller i artiklen. Ikke mere om det her.
10. Alan Turings filosofiAlan Turings filosofi i sit arbejde på Bletchley Park var at udføre dekrypteringsarbejde, som virkede, ikke bare at udvikle nyttesløs teori. Udover at være en teoretiker, var han således også en eksponent for konkret og praktisk anvendelse af matematik. Han udtrykte blandt andet selv følgende i forbindelse med Banburismus: When the whole evidence about some event is taken into account it may be extremely difficult to estimate the probability of the event, even very approximately, and it may be better to form an estimate based on a part of the evidence, so that the probability may be more easily calculated.
11. MaterialeNedenfor kan downloades forskellige filer. En fil, hvor det danske alfabet bruges og en fil, hvor det engelske alfabet bruges. Bemærk, at Maple filerne kræver installation af Gym-pakken for at få filerne til at virke. Kan hentes gratis her: https://www.maplesoft.com/maplegym/ Maplefil til at bestemme nøglen ved hjælp af Alan Turings statistiske metode - DANSK Vigenère tabel - DANSK sprog
12. Litteratur/links
Denne side er skrevet i juli 2023. |
|
|