Alle links
Gymnasie links
Andre links
Regler
Faglig forening

RetsgenetikEfter at have studeret, hvordan Bayes formel i matematik kan bruges til at afdække nogle nærliggende fejltagelser, som man kan begå i en retssal i forbindelse med DNA-sager (se siden: Bayes fantastiske formel), dukkede det næste spørgsmål op: Hvordan i alverden fungerer det med DNA, og hvorfor kan det bruges til at bestemme match-sandsynligheder? Det skulle vise sig at være en forunderlig verden af meget små biologiske dele, hvori der hersker en forbavsende systematik. Biologer og kemikere har fundet på snedige procedurer til at "aflure" naturens fascinerende lovmæssigheder og til at bestemme DNA-profiler for mennesker og dyr. Sidstnævnte handler om at "aflæse" biologiske elementer i størrelsesordenen få nanometer. Udover at læse om emnet fik jeg også lejlighed til at besøge Retsgenetisk Afdeling i København. NB! Klikker man på et billede, vises i mange tilfælde en større udgave.
1. Besøg på Retsgenetisk Afdeling i KøbenhavnSommeren 2016 besøgte jeg Retsgenetisk Afdeling i København. Afdelingen hører under Retsmedicinsk Institut, som igen er en del af det Sundhedsvidenskabelige Fakultet på Københavns Universitet. Jeg havde fået en aftale i stand med biologen Jakob, som velvilligt fortalte mig om arbejdsgangen på afdelingen og om, hvordan DNA-profiler bliver anvendt i blandt andet retssager og faderskabssager. Retsgenetisk afdeling i København er det eneste sted i Danmark, hvor man bestemmer DNA-profiler i forbindelse med retssager. I Aarhus har man også et retmedicinsk institut, men her foregår kun undervisning i retsgenetik.
Biologiske sporI forbindelse med retssager vil kriminalteknikere lede efter spor på gerningsstedet. Det kan være sæd, blod, spyt eller lignende på tøj eller på våben, eller biologisk materiale afsat under en persons negle. Det er kun efterforskerens fantasi, der sætter grænsen. De biologiske spor sikres ofte ved, at man aftørrer genstande med en vatpind. Vatpindene sendes i en sikret emballage til Retsgenetisk Afdeling. I tilfældet med tøj kan man evt. sende beklædningsgenstanden til afdelingen. Her vil man
undersøge tøjet overfladisk for blandt andet sæd, blod eller
spyt. På Retsgenetisk
afdeling laves et ekstrakt af det biologiske spor, før det kan analyseres nærmere. Her anvendes forskellige biokemiske processer. DNA fra mistænktEn mistænkt kan typisk blive anmodet om at afgive en DNA-prøve ved at man foretager et mundskrab på indersiden af kinden med en vatpind. Den mistænktes genetiske fingeraftryk sammenlignes med DNA fundet på gerningsstedet.
DNA fingeraftrykI processen med at bestemme DNA-fingeraftrykket, også kaldet sporets DNA-profil, anvendes to delprøver. Det kontrolleres, at resultatet bliver det samme begge gange. Derved minimeres risikoen for fejl. Delprøverne analyseres uafhængigt af hinanden. I øvrigt er personalet i lokalerne iført en dragt, som skal forhindre deres eget DNA i at blandes med det fra delprøverne. Endvidere er der styring af lufttrykket i rummene for at mindske risikoen for, at der kan spredes DNA fra det ene rum til det andet. Der er i det hele taget en stor grad af kontrol. De processer, prøverne bliver udsat for, er PCR (Polemerase Chain Reaction) for at opformere mængden af DNA og siden kapillarelektroforese for at adskille og registrere STR-regioner (se afsnit 4) med forskellige længder. De biologiske og tekniske pointer i den forbindelse er beskrevet i afsnittene 2-7 herunder. DNA skal opbevares omhyggeligt, fordi det vil nedbrydes af bakterier, fugt, varme og lys. Man kan bestemme DNA-profiler ud fra mængder helt ned til 0,5 ng, svarende til omtrent 100 diploide celler!
EvalueringNår DNA-profilerne fra gerningsstedet og fra tiltalte foreligger, kan man foretage en sammenligning. Hvis profilerne er ens, vil man udregne en match-sandsynlighed, som er et estimat af sandsynligheden for, at en tilfældig valgt person, som ikke er i nær familie med den pågældende, vil have samme DNA-profil som det foreliggende. Du kan læse mere om, hvordan match-sandsynligheder udregnes i afsnit 9. Tager man den reciprokke værdi af match-sandsynligheden, får man - i de fleste tilfælde - den såkaldte Likelihood Ratio (likelihood-kvotienten LR), som er omtalt i afsnit 10. Likelihood-kvotienten anføres i den retsgenetiske erklæring og udtrykker, hvor mange gange mere sandsynligt det er at observere resultatet (DNA-matchet), hvis sporet faktisk stammer fra personen, end hvis sporet stammer fra en tilfældig, anden person i en relevant befolkningsgruppe. De største værdier for likelihood-kvotienten, man melder ud i Danmark er > 1.000.000 (større end 1 mio.). Selv om man ofte udregner en LR, som er meget større, så vælger man i DK at være meget konservativ. Det gør man, fordi der er en række usikkerheder involveret. En lille LR vil komme den anklagede til gode. Likelihood-kvotienter kan godt blive mindre end en million, hvis der på gerningsstedet er fundet blandinger af DNA, som resulterer i blandingsprofiler. Et andet tilfælde er, hvis DNA'et er beskadiget, og man fx ikke kan bestemme allelerne i bestemte loci. I tilfældet med faderskabssager er den største LR, man meddeler: > 10.000 (større end ti tusinde). En retsgenetiker kan blive anmodet om at møde op til en retssag for at redegøre for betydningen af likelihood-kvotienten.
DNA-registerPolitiet i Danmark oprettede i år 2000 et DNA-register. I år 2005 blev DNA sidestillet med fingeraftryk hvad angår indsamling og registrering. Det betyder, at man indsamler og registrerer DNA-profiler fra personer, som er eller har været sigtet i sager, som kan give fængsel fra 1 år og seks måneder og opefter i straf og i visse tilfælde med børnepornografi. Databasen består af:
Der er også regler for, hvornår data skal slettes. Du kan læse mere om det her. Uddannelse af rettens aktørerJakob, der har haft efteruddannelse i statistik og matematik, står også for kurser for "rettens aktører" herunder anklagere, advokater og dommere. Det handler om at forstå DNA-bevisets vægt rigtigt. Som omtalt andetssteds (fx her) er der mange faldgruber i fortolkningerne af de resultater, som retsgenetikerne videregiver til retten. "Jurister og genetikere taler forskellige sprog" og "Jurister er trygge ved ord, retsgenetikere er glade for tal", som der står i noget af kursusmaterialet. Målsætning for uddannelse af rettens aktører:
Alt sammen med det formål at dommene bliver afsagt på det rette grundlag. Du kan læse mere om problematikken i en artikel i et magasin fra Danmarks Domstole: Se linket [L1] under Links.
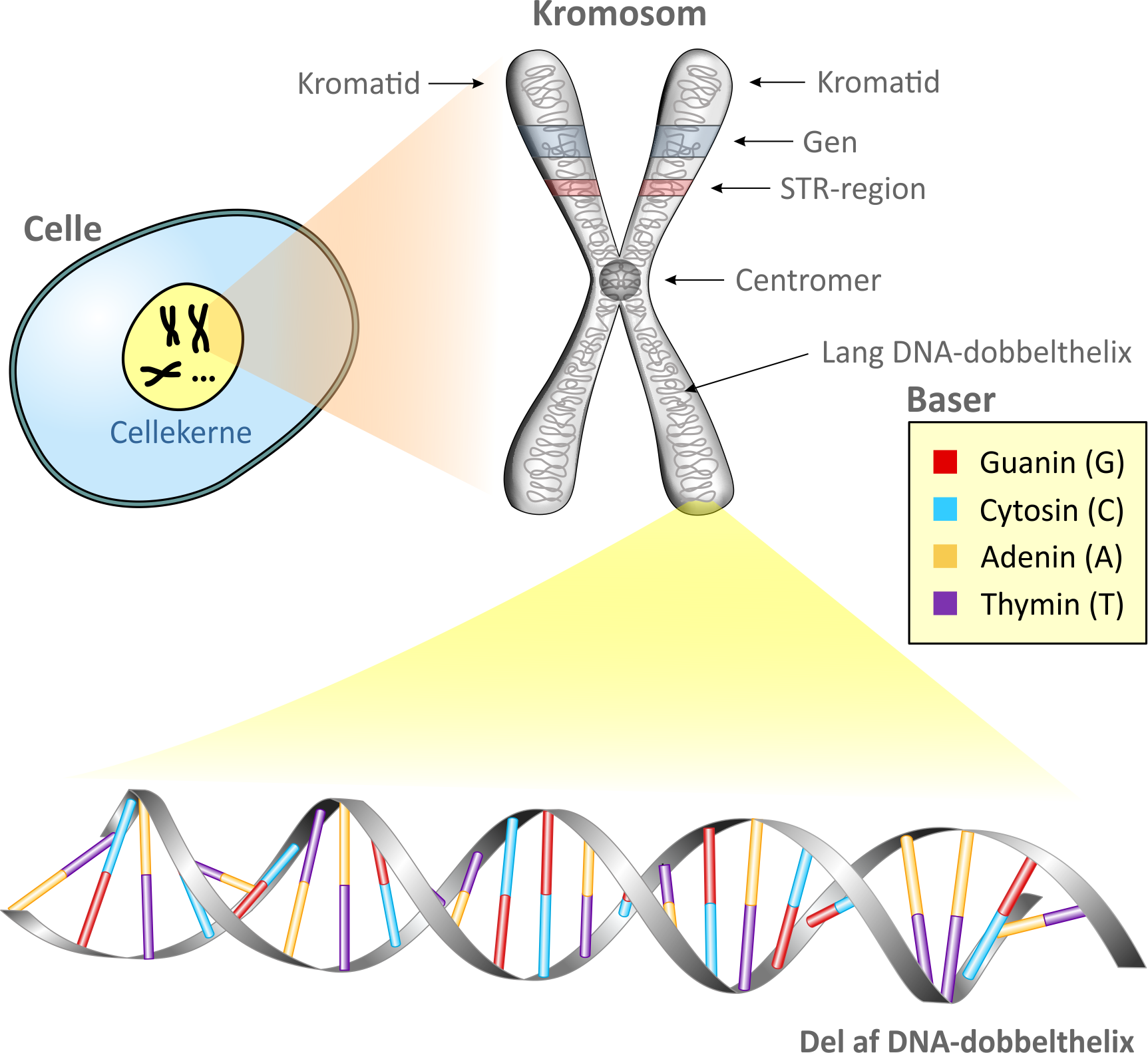
2. Celler, kromosomer og generLad os begynde med lidt biologi. De almindelige (diploide) celler hos et menneske indeholder 23 kromosompar, mens kønscellerne (haploide celler) indeholder 23 enkelt-kromosomer. Kromosomerne befinder sig i cellekernen, som vist på figuren nedenfor. Da kromosomet er vist under en celledeling, fremstår kromosomet med to ens kopier kaldet kromatider, hæftet sammen via et centromer. Hvert kromatid består af proteiner samt en meget lang DNA-dobbelthelix. Sidstnævnte kommer vi nærmere ind på i næste afsnit. I en diploid celle vil der befinde sig to kromosomer, hvor det ene indeholder arvemateriale fra faderen og det andet indeholder arvemateriale fra moderen. Langt den største del af en DNA-dobbelthelix er identisk fra person til person. De områder i dobbelthelixen, hvor generne sidder og hvor de såkaldte STR-regioner - også betegnet mikrosatelitter - findes, er der derimod variationer. Generne indeholder en del af menneskets arvemasse også kaldet genomet. Den genetiske variation giver sig til udtryk ved, at hvert gen findes i et antal forskellige udgaver, kaldet alleler. Et gen på kromosom nummer 15 har således mulighed for en (dominant) allel for brune øjne og en (vigende) allel for blå øjne. Det betyder, at hvis det pågældende gen på kromosom nr. 15 hos en person for eksempel indeholder en allel for brune øjne fra moderen og en allel for blå øjne fra faderen, så fremtoner personen med brune øjne. Man siger at fænotypen for øjenfarve i dette tilfælde er brune øjne. Hvis personen derimod har en allel for blå øjne fra både moderen og faderen, så fremtoner personen med blå øjne. Generne kan betragtes som en "opskrift" for de proteiner og forskellige andre molekyler, som en celle kan producere. Proteinerne er bestemmende for personens fremtoning og egenskaber. STR-regionerne derimod er specielle derved, at de indeholder en række repetitioner af basepar, som vi skal komme ind på et par afsnit længere fremme. Antallet af repetitioner af disse basepar varierer fra person til person og er derfor meget hensigtsmæssige at anvende i retsgenetikken.
Et gens placering i et kromosom betegnes dets locus (flertal loci). Et eksempel er ind-tegnet på figuren. Hvis det pågældende gen er det for brune/blå øjne, kan det være, at genet er repræsenteret ved allelen for brune øjne (B) på det ene kromosom og allelen for blå øjne (b) på det andet kromosom. Man siger i så fald, at personen har genotype Bb. På figuren er også indtegnet en placering (locus) for en STR-region i kromosomet. Hvis STR-regionen indeholder 9 repetitioner på det ene kromosom og 12 repetitioner på det andet, siger man, at personen har allelerne 9 og 12 på det pågældende locus. Det skrives (9,12). I virkeligheden er der mange gener og STR-regioner på hvert kromosom.
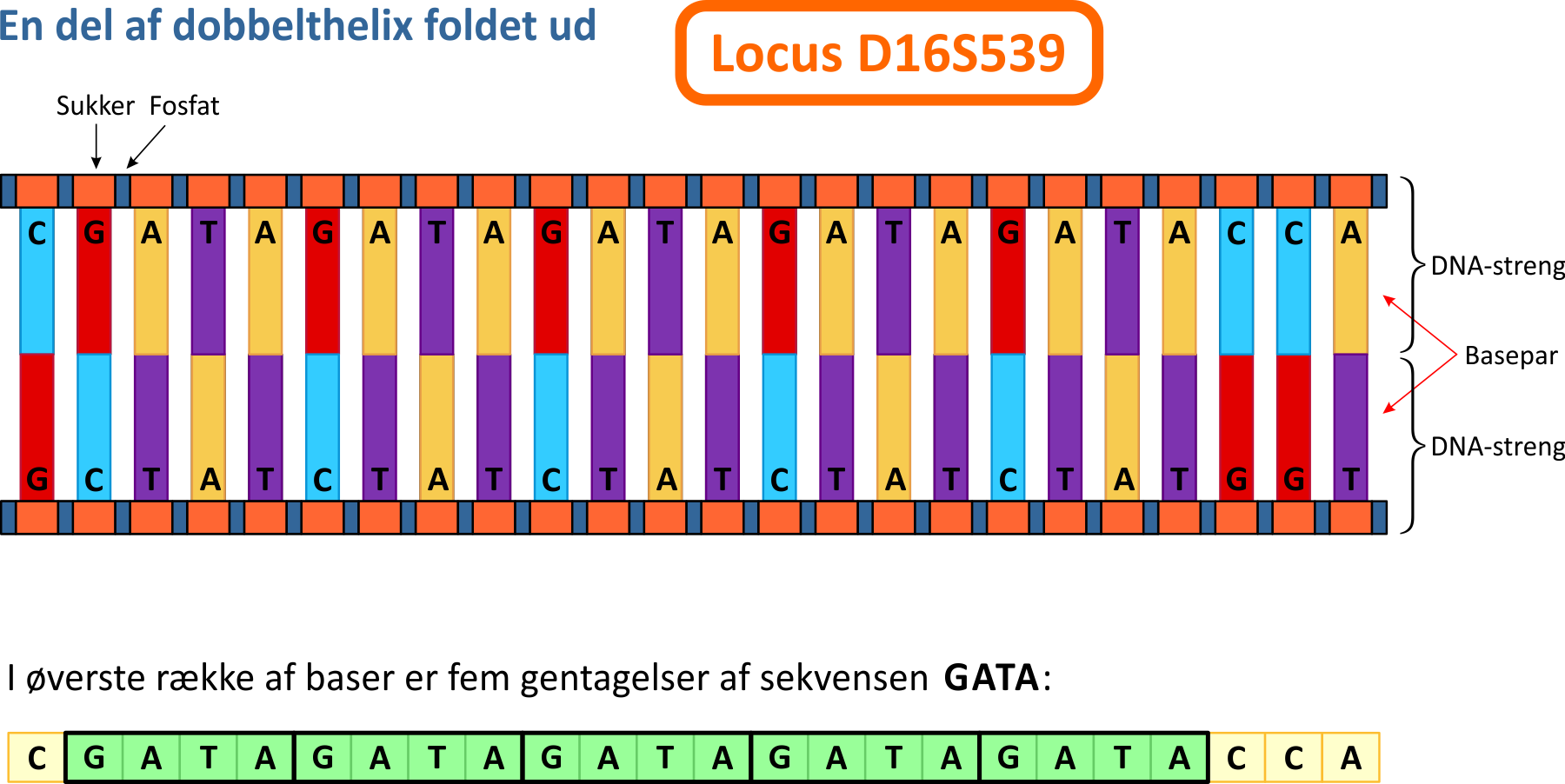
3. DNA dobbelthelixEn dobbelthelix består af to DNA-strenge, hvis rygrad matematisk set danner to skrue-linjer eller vindellinjer. På den måde er "den biologiske information" lagret på en meget kompakt måde. Den muliggør i øvrigt også en hensigtsmæssig og enkel celledeling, som dog ikke er temaet her. Den amerikanske biolog James Watson og den engelske fysiker Francis Crick beskrev i 1953 strukturen af DNA. Sammen med fysiker og molekylær-biolog Maurice Wilkins fra New Zealand modtog de Nobelprisen i fysiologi og medicin i 1962 "for their discoveries concerning the molecular structure of nucleic acids and its significance for information transfer in living material". Opdagelsen af dobbelthelix-strukturen i DNA er en af milepælene indenfor biologisk forskning. Figuren ovenfor viser også en ganske lille del af den uhyre lange DNA-dobbelthelix. Man observerer desuden, at de to DNA-skruelinjer er forbundet med basepar. De fire involverede baser er Guanin (G), Cytosin (C), Adenin (A) samt Thymin (T). Det viser sig, at parrene altid kun forekommer i kombinationerne G-C og A-T, bundet sammen af hydrogenbindinger. Det skal tilføjes, at delfiguren af DNA dobbelthelixen kun er en simpel model. Geometrisk betragtet er baserne ikke "stave"; baserne og de kemiske bindinger danner en ikke-simpel geometrisk struktur. Desuden er skruelinjerne ikke helt så symmetriske, som modellen viser. Den ene skruelinje i B-DNA er forskudt en smule langs omdrejningsaksen. Man taler således om den store rille (major groove) og den lille rille (minor groove). Disse kendsgerninger har dog ikke nogen betydning for de kommende forklaringer. Diameteren i dobbelthelixen er af størrelsen 2,0 nm (nanometer). For hver omdrejning i en skruelinje "bevæger skruen sig 3,4 nm fremad". Der er i gennemsnit ca. 10,4 basepar pr. omdrejning.
4. Short Tandem Repeats (STR)Tilbage til de såkaldte STR-regioner i DNA'en. Lad os forestille os, at skruelinjerne "rettes ud", så de udgør to linjer. På figuren nedenfor betragter vi den del af DNA-dobbelthelixen (udfoldet), som indeholder et STR-locus med navnet D16S539. Betegnelsen hentyder til locus nummer 539 på kromosom nr. 16. Der er tale om et af de områder i DNA'en, som varierer fra person til person og som ofte benyttes til DNA-profiler.
Hos alle personer er det basesekvensen GATA, som optræder her, mens det, der varierer, er antallet af gange, sekvensen gentages. I ovenstående tilfælde vil man sige, at personen har allel 5 på locus D16S539, fordi sekvensen har fem gentagelser. I cellen vil der også være en allel på det samme locus på det andet kromosom. Hvis denne allel er 13, vil personen have allelkombinationen (5,13) på det pågældende locus. Figuren viser i øvrigt også, at DNA-strengene består af skiftevise sukker- og fosfat-grupper. Kombinationen af en sukkergruppe, én eller flere fosfatgrupper samt en af de fire baser, der i øvrigt betegnes et nukleotid.
5. DNA-sekventeringEfter opdagelsen af den dobbelte helix-struktur opstod hurtigt ønsket om at kunne "aflæse" baserne i DNA-strengene. Men hvordan i alverden kan man aflæse baserne, når de biologiske dele har dimensioner i størrelsesordenen nanometer? Den første person, som anviste en metode hertil var den britiske biokemiker Frederick Sanger. Sammen med to andre forskere, indbragte metoden ham Nobelprisen i kemi i 1980. DNA-sekventering kan bruges til blandt andet at bestemme et helt genom (arvemasse) for et dyr eller et menneske. Den første fuldstændige sekvens af DNA fra en bakterievirus, der består af 5386 basepar, blev publiceret i 1977 af Frederick Sanger. Ikke overraskende satte forskere i 80'erne sig det mål at sekventere menneskets arvemasse, som indeholder ca. 3,2 mia. basepar. Human Genome Project, koordineret af organisationen HUGO (The Human Genome Organisation), startede i 1990. I 2004 havde man klaret opgaven. I 2007 fik man sekventeret en bestemt persons DNA, nemlig James D. Watson – den ene opdager af DNA dobbelthelixen.
6. DNA-fingeraftrykDen første person til at anvende DNA i forbindelse med retssager var en britiske professor i genetik fra University of Leicester, Sir Alec Jeffreys. I 1984 opdagede han en metode til at påvise variationer i menneskers DNA. Denne opdagelse lagde grunden til, at han og hans team i det følgende år udviklede metoder til det, der i dag betegnes genetisk fingeraftryk eller DNA fingeraftryk. Teamet anvendte godt nok ikke alleler fra STR-loci, men derimod alleler fra VNTR-loci (minisatellitter). Eneste forskel er, at her er base-sekvenserne blot lidt længere end tilfældet er for STR-loci (mikrosatellitter). Mens VNTR-loci typisk har base-sekvenser af længden 10-60, har STR-loci typisk base-sekvenser af længden 2-6. VNTR står for Variable Number Tandem Repeats, mens STR jo står for Short Tandem Repeat. Senere er man gået over til at anvende STR-loci, som er mere robuste. Der var også en anden ulempe ved den oprindelige procedure: den krævede relativt store prøver af DNA.
Jeffreys DNA metode blev først anvendt i praksis i 1985 i forbindelse med en britisk immigrationssag, hvor DNA resultaterne beviste, at en dreng var i tæt familie med medlemmer af en ghanesisk familie. Første gang metoden blev anvendt i en kriminalsag var i en sag fra Narborough, Leicestershire i England, hvor to teenagepiger var blevet fundet voldtaget og myrdet i henholdsvis 1983 og 1986. Ved en DNA screening af mistænkte blev Colin Pitchfork udpeget som den skyldige i begge mord. Sagen var antagelig særlig vigtig for udbredelsen af DNA i retssager, fordi DNA udpegede en anden person end den hovedmistænkte. Britiske myndigheder har efterfølgende givet udtryk for, at uden DNA-beviset ville en forkert person sandsynligvis være blevet dømt i sagen. Colin Pitchfork erkendte da også mordene og fik en livstidsdom.
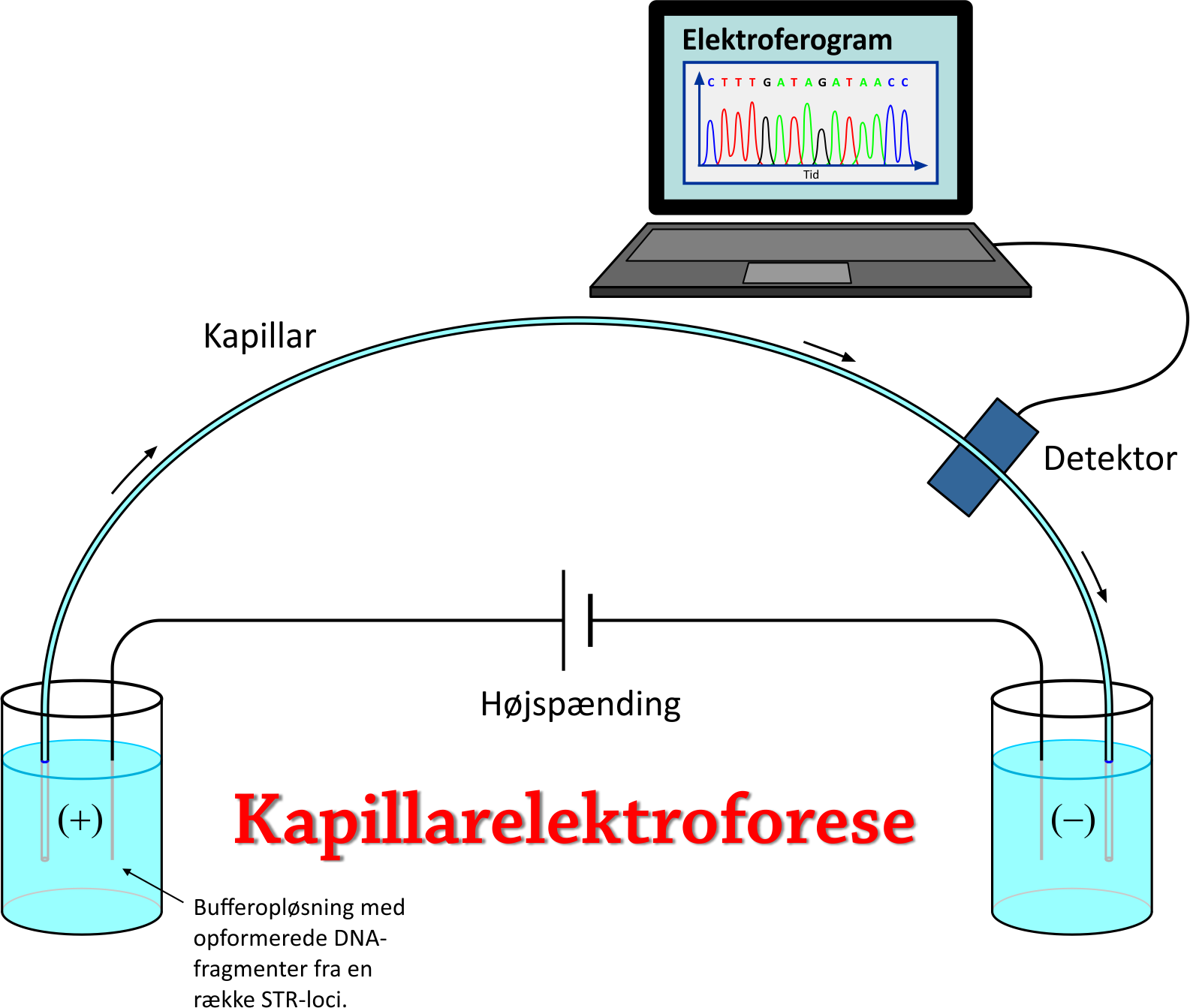
7. PCR og kapillarelektroforeseI 1987 blev DNA fingerprinting kommercialiseret og har siden løbende undergået en rivende udvikling, så prøverne er blevet billigere at foretage, hurtigere at udføre, og der kræves mindre og mindre DNA i en prøve for at en DNA-profil kan bestemmes. Hvad angår sidstnævnte, så var en af de helt store landvindinger, da man opdagede en måde at kopiere et givet stykke af et DNA-fragment i en masse kopier. Derved kunne man bestemme DNA-profilen, selv om der oprindeligt kun var ganske lidt DNA til stede på gerningsstedet. Kopieringsteknikken går under navnet PCR (Polymerase Chain Reaction). Kort fortalt sker der følgende: Et DNA-fragment befinder sig i en bufferopløsning, hvori der også er taq DNA polymerase, nukleotider og såkaldte primere. Lad os sige, at DNA-fragmentet indeholder de 5 gentagede basesekvenser fra locus D16S539 fra figuren ovenfor samt et lille stykke DNA på hver side deraf. Vi ønsker at opformere (kopiere) stykket med de 5 gentagede basesekvenser. Først opvarmes opløsningen til ca. 95°C, så DNA-dobbelthelixen skilles i to DNA-strenge. Temperaturen sænkes til ca. 60°C, så en primer genkender og sætter sig på hver DNA-streng afgrænsende hver sin ende af det interessante stykke af DNA'et, som man ønsker at kopiere. Temperaturen øges til 72°C. Polymerasen er et enzym, som nu hjælper med at sætte de frie nukleotider på DNA-strengene, så hver DNA-streng bliver til en ny dobbelthelix. Nævnte proces gentages, og for hver gentagelse fordobles antallet af DNA-fragmenter. Når det er gjort mange gange står man med over en milliard DNA-fragmenter, hvor langt hovedparten består af netop det søgte område med de gentagede basesekvenser fra locus D16S539. Detaljerne kan du eventuelt se ved at kigge på linket [L8], som viser hen til en YouTube video. Efter PCR indeholder opløsningen altså over en mia. kopier af DNA-stykket med de fem gentagede basesekvenser, repræsenterende allelen på locus D16S539. Det samme er tilfældet for allelerne på alle de øvrige udvalgte loci i DNA'et. Typisk benyttes 13 eller 16 forskellige loci. Det eneste der mangler nu, er at kunne adskille de forskellige alleler fra hinanden med henblik på at kunne konstatere, hvor mange gentagelser, der er på hvert STR-loci. Når man har gjort det, har man DNA-profilen. Her gør man brug af en separationsteknik, som kaldes kapillarelektroforese. Idéen er at udsætte de negativt ladede DNA-segmenter for et elektrisk felt, så de bevæger sig igennem et tyndt rør (kapillar). Det viser sig, at jo længere DNA-segmenterne er, jo langsommere bevæger de sig igennem kapillaren. Princippet er vist på figuren nedenfor. Linket [L9] nedenfor viser desuden hen til en YouTube video, som beskriver processen.
Det skal tilføjes, at allerede før PCR-fasen har de frie nukleotider fået tilføjet et farvestof – én farve for hver af de fire forskellige baser C, G, A og T. Når et DNA-fragment bevæger sig forbi en detektor, vil en Argon-ion-laser excitere atomerne i farvestoffet, så de lyser. Lyset opfanges af et CCD-kamera, som sender data til en computer. Det giver anledning til et elektroferogram. Ved hjælp heraf kan man registrere hvilke baser, som er i DNA-segmentet og dermed afklare, hvilke locus, det pågældende DNA-segment hører til. Den tid, det tager hver type DNA-segment at nå detektoren, kan samtidigt bruges til at bestemme, hvor mange repetitioner af basesekvensen, der er i det betragtede STR-locus, dvs. bestemme allelen på dette locus. Som nævnt bevæger lange DNA-segmenter sig langsomt og korte DNA-segmenter sig hurtigt i kapillaren. For at kunne fastslå antallet af repetitioner er man desuden nødt til også at have nogle reference-DNA-segmenter med kendte længder – for at kunne foretage en sammenligning - kaldet allel-stige eller Allelic Ladder.
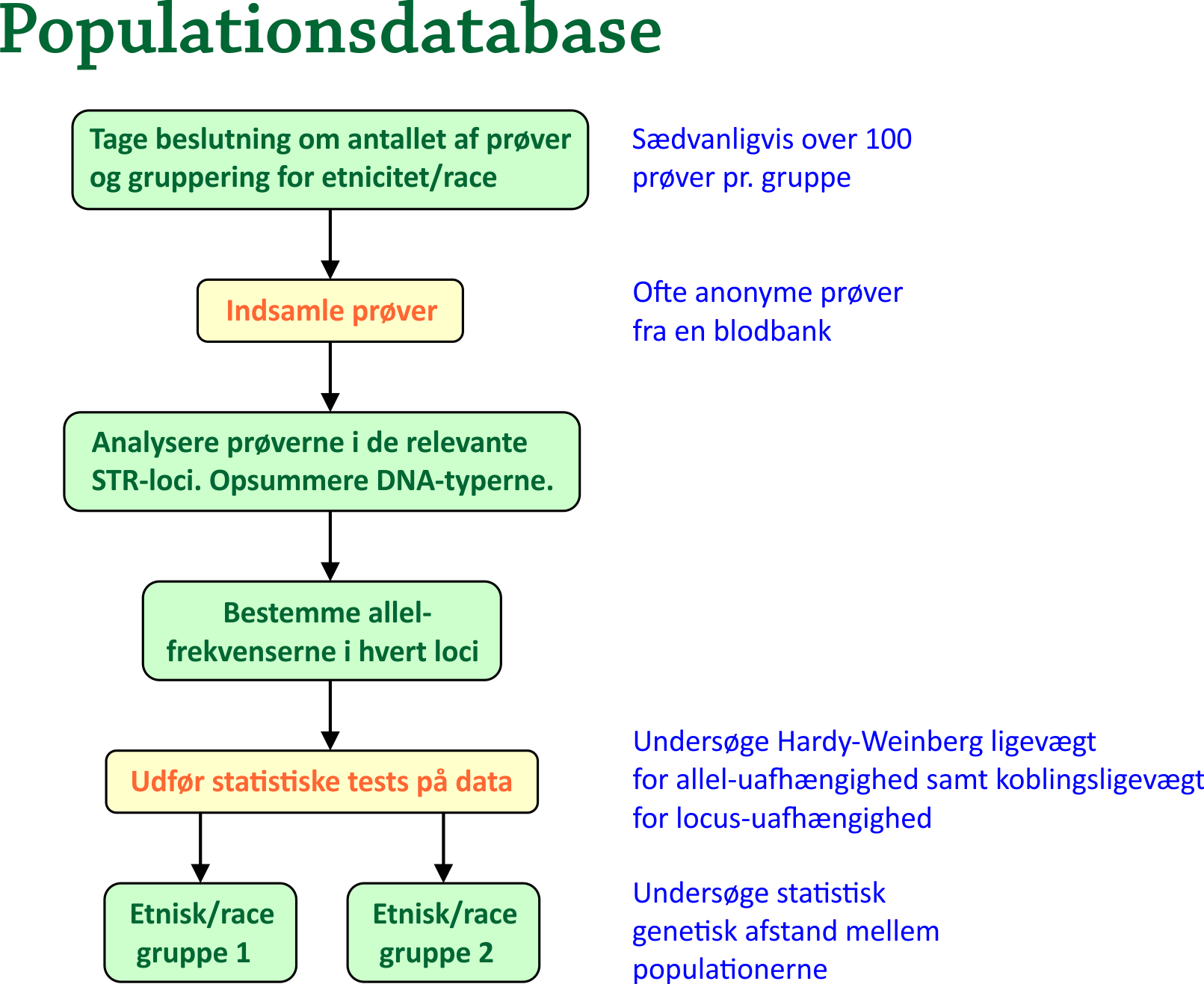
8. Populations databaseDet er indlysende, at hvis man vil udregne sandsynligheden for en bestemt DNA-profil, så må man have noget at sammenligne med. Hvor stor en procentdel af en given population har den ene og den anden allel på et givet loci? Bogen [2] af Butler giver et fremragende indblik i denne problematik. For at fremstille en populationsdatabase, gør man typisk det, at man tager en række prøver fra hver etniske/racemæssige gruppe i populationen. Antallet af prøver bør være over 100 i hver gruppe. Man er interesseret i allel-frekvenserne i en række STR-loci (I USA bruges 13, i Danmark bruges 16). I praksis gør man helt simpelt følgende: For hvert locus optælles, hvor ofte hver allel forekommer i prøverne, hvorefter man dividerer med det samlede antal alleler fra prøverne på det pågældende locus. Analyser har vist, at for hvert locus og hver gruppe, er det tilstrækkelig med 100-200 alleler, for at man kan bruge resultaterne til senere at foretage robuste likelihood beregninger. En inddragelse af væsentlig flere prøver vil normalt ikke afgørende ændre på frekvenserne; den vil kun gøre de sjældne alleler mere sikre. Det sidstnævnte bør overvejes en ekstra gang: Det kunne jo være, at der i prøverne slet ikke forekom en bestemt allel. Med metoden ovenfor ville det medføre, at allel-frekvensen for den pågældende allel var 0. Skulle det så vise sig, at en mistænkt person i en sag rent faktisk har den pågældende allel, så ville man ende op med en match-sandsynlighed på 0, hvilket man selvfølgelig ikke kan have. Det anbefales, at hvis en allel skal indgå i beregninger af en match-sandsynlighed, så bør den pågældende allel være forekommet mindst 5 gange i databasen. Den minimale allel-frekvens i databasen bør derfor være 5/(2N), hvor N er antallet af personer, hvorfra der er taget prøver, hvilket giver 2N alleler på hvert loci, eftersom allelerne forekommer i par. Hvis en allel-frekvens efter den første beregning er under dette tal, så sætter man den simpelthen til at være 5/(2N) DNA-prøverne, som anvendes til at bestemme allel-frekvenserne, fås ofte fra en blodbank, hvor blodet er fra anonyme bloddonorer, som selv har opgivet deres etnicitet. Efter man har bestemt STR-allelerne i prøverne, udsætter man data for statistiske tests på en computer. Herunder er især to tests vigtige: Test for Hardy-Weinberg ligevægt: Tester uafhængigheden af allelerne på det samme locus. Som bekendt vil en population allerede efter én generation indtræde i en ligevægt kaldet Hardy-Weinberg ligevægten, såfremt følgende er opfyldt:
Betingelserne medfører - hvilket vi undlader at vise her - at der vil være en konstant allel-frekvens i populationen og genotype-frekvenserne vil adlyde nogle bestemte formler:
Noget andet er, at det er nærmest umuligt for en population at opfylde alle betingelserne. Alligevel er det den ideelle situation, man har som udgangspunkt. I mange tilstrækkeligt store populationer vil den da også ofte være nogenlunde opfyldt. Nævnte test for Hardy-Weinberg ligevægt kan enten foretages ved en Chi-i-anden Goodness of Fit test eller ved Fishers Exact Test. Vi skal ikke gå nærmere ind på det her. Heller ikke testen for koblings-ligevægt, som skal godtgøre, at alleller hørende til forskellige loci er uafhængige, skal vi gå i detaljer med.
9. Match-sandsynlighederVi skal i første omgang præsentere den simpleste model til beregning af match-sandsynligheder, også betegnet Random Match Probability (RMP). Den bygger på den genotypefordeling, som Hardy-Weinberg ligevægten forudsiger (se afsnit 8). Autentiske populationer kan dog imidlertid kræve justering på grund af population understruktur (population substructure). Vi vil undlade at gå ind i den problematik her.
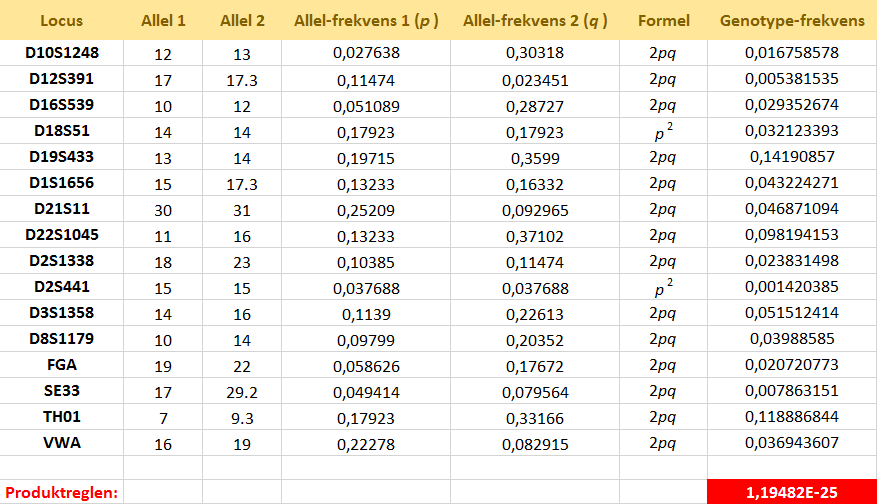
Lad os se på et konkret eksempel på bestemmelse af en match-sandsynlighed. Vi antager at DNA'et på gerningsstedet har profilen, som vist i skemaet nedenfor. Det skal forstås på den måde, at STR-locus D10S1248 indeholder allel-kombinationen 12,13, at STR-locus D12S391 indeholder allel-kombinationen 17,17.3, etc. I øvrigt betyder alleler med kommatal, at der ikke er et helt antal gentagelser af base-sekvensen, men en smule mere. I skemaet står også anført allel-frekvenserne for de involverede alleler. De er realistiske værdier fra en populationsdatabase og kan findes i denne Excel-fil:
Der er tale om værdier bestemt i et studium udført af Carmen Tomas Mas, Helle Smidt Mogensen, S. L. Friis, C. Hallenberg, M. C. Stene og Niels Morling. [L4] under Links vises et link til den artikel, som forfatterne har skrevet i et amerikansk tidsskrift FSI Genetics. Det drejer sig om allel-frekvenser for danskere, grønlændere og somaliere. Forklaring: Da STR-locus D10S1248 er heterozygot her, fås sandsynligheden for denne genotype ifølge Hardy-Weinberg ligevægten (HW) ved at tage det dobbelte af produktet af de to allel-frekvenser. Tilsvarende med de øvrige heterozygote loci. Locus D18S51 er derimod homozygot, hvor sandsynligheden for denne genotype fås ved at opløfte allel-frekvensen til 2. potens. Når man har alle genotypefrekvenserne, fås den samlede match-sandsynlighed ved at multiplicere alle genotype-frekvenserne,
hvilket kan gøres under antagelse af uafhængighed mellem de forskellige loci.
Til højre under skemaet kan du finde en Excel-fil med samme data, som er i skemaet. Nu har vi ovenfor benyttet allel-frekvenserne for danskerne. Men man kan stille sig selv det spørgsmål om, hvornår skal man bruge hvilken population? Du kan læse mere om det ved at kigge i følgende artikel: Guide til dna som bevis af Hans Jakob Larsen, Kari Sørensen (2013).
10. Likelihood Ratio i rettenFor at vurdere værdien af et DNA bevis foretrækker man ofte i retten at anvende den såkaldte Likelihood Ratio, forkortet LR fremfor match-sandsynligheden omtalt i afsnit 9. Forholdet LR, som på dansk undertiden også omtales som Likelihood-kvotienten, indgår i Bayes' formel på odds form, der lidt kortfattet og indforstået kan udtrykkes således:
Vurderingen af FORHÅNDS-ODDS er typisk overladt til dommer og/eller nævninge at vurdere (evt. verbalt). LR derimod er det tal retsgenetikeren kommer med. Det fortæller noget om DNA-bevisets styrke. Ganges de to størrelser sammen, fås de nye opdaterede odds. Lad os for eksempel antage at dommeren/nævningene ud fra diverse oplysninger på forhånd vurderer, at det er 100 gange mere sandsynligt, at tiltalte er uskyldig, end at tiltalte er skyldig. Så er FORHÅNDS-ODDS lig med 1/100 eller 0,01. Hvis nu det viser sig, at tiltaltes DNA matcher DNA'et på gerningsstedet og lad os sige, at vi har den meget lille match-sandsynlighed fra eksemplet i afsnit 9, som vil give en kæmpe værdi for LR, så vil retsgenetikeren meget konservativt (til fordel for tiltalte) sætte LR ned til 1.000.000. Ganger vi de to tal sammen, altså 0,01 og 1.000.000, så fås de opdaterede ODDS til 10.000. Nu er det pludselig 10.000 gange så sandsynligt, at tiltalte er skyldig, som at tiltalte er uskyldig! LR øger altså forholdet mellem sandsynligheden for skyld og sandsynligheden for uskyld med en faktor 1 mio. Det er ofte afgørende i en retssag. Det skal dog tilføjes, at hvis FORHÅNDS-ODDS er meget små, så er det ikke sikkert, at DNA-beviset kan gøre ODDS tilstrækkeligt stor til at fælde dom. Det er derfor man bør kræve yderligere information udover DNA. Er DNA-matchet tilvejebragt via en databasesøgning, og ikke bare ved DNA-prøver fra et mindre antal mistænkte, er anden information om den matchende person vigtig. Der skal være flere ting, som kan koble personen til ugerningen. Det skal afslutningsvist bemærkes, at hvis vi kalder sandsynligheden for at tiltalte er skyldig for p, så kan den findes af ODDS ud fra følgende formel:
Beviset herfor overlades til læseren. Vi skal se på et opdigtet eksempel på bestemmelse af Odds.
Eksempel Der er foregået et større tyveri på en fabrik. Ved den lejlighed er der opsamlet DNA på stedet, som desværre er af ret ringe kvalitet. Politiet sammenligner det med DNA fra en række kendte kriminelle. Her viser det sig, at der er et delvist match. Personen med det delvise match sigtes. Man har i samme ombæring konstateret, at den mandlige person var i byen på tidspunktet for tyveriet. Man har også undersøgt hans whereabouts på gerningstidspunktet med mere. Alt i alt vurderer nævningene, at odds for, at tiltalte er skyldig - før viden om DNA - er 1:10000, altså 0,0001. Det er også det, som kaldes FORHÅNDS-ODDS eller a priori odds. Retsgenetikeren møder op til retsmødet, hvor denne bekendtgør, at LR eller Bayes-faktoren er beregnet til at være 75000. Vi kan hermed udregne de "opdaterede odds" efter viden om DNA. De kaldes ofte bare for ODDS eller for a posteriori odds. De fås af Bayes' formel på odds form:
At det kun er 7,5 gange så sandsynligt, at tiltalte er skyldig, som at han ikke er skyldig, er for lidt til domfældelse. Altså frikendes personen. NB! Beregn evt. sandsynligheden p for skyld via formlen lidt ovenfor! Bemærk, at ovenstående er sat på spidsen: Nævningene angiver normalt ikke en forhåndssandsynlighed. Det gør retsgenetikerne derimod. Derfor bliver det normalt en helhedsbedømmelse af situationen ... Matematisk
Formlen indeholder betingede sandsynligheder. De konkrete hændelser er i denne forbindelse følgende:
vel at mærke med de ovennævnte simplifikationer, såsom at sidestille hændelsen "tiltalte afsatte DNA-sporet på gerningsstedet" med hændelsen "tiltalte er skyldig". Læseren opfordres til at overbevise sig om, at ovenstående fører til ODDS 7,5.
Du kan læse meget mere om Bayes' formel på odds form på min side Bayes' fantastiske formel. Klik eventuelt på nedenstående label for at komme dertil. Det er gennemgået mere i dybden i min e-bog på samme side.
11. FaderskabssagerMan benytter også DNA beviser udenfor kriminalretten, fx i en civilret, hvor man ønsker at afgøre en faderskabssag. Er en mand den biologiske far til et bestemt barn eller ej? Bogen [5] giver et udmærket billede af den problemstilling, som gør sig gældende her. Man kender moderens og barnets alleler på de relevante STR-loci. Derudover kendes også allelerne for den mand, som man vil teste for at være den biologiske far. Som sædvanlig søger retsgenetikerne at bestemme en Likelihood-kvotient, her benævnt PI for Paternity Index - på dansk faderskabsindeks. Man kan bestemme PI for hvert enkelt locus og derefter multiplicere dem sammen til en samlet værdi for PI. Ved som sædvanlig at gange likelihood-kvotienten (her PI) på forhånds-odds, kan man få de opdaterede odds for faderskab. Vi har følgende:
Lad os sige, at man ved en beregning kommer frem til, at PI = 100000. Det kan da fortolkes på følgende måde: Sandsynligheden for at se barnets genotype, givet kendskab til moderens genotype og den rigtige faders genotype, er 100000 gange så stor som sandsynligheden for at se barnets genotype, givet kendskab til moderens genotype og viden om at en vilkårlig anden mand er fader til barnet. En smule mere løst:
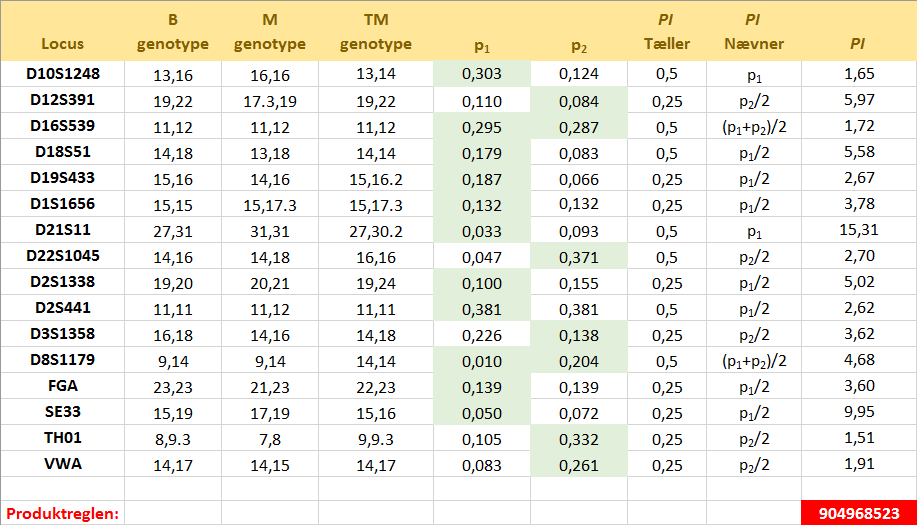
Som bekendt har personer, der er i nær slægtskab med hinanden, mere ensartet DNA. Derfor kan det i en konkret faderskabssag nogle gange være relevant at undersøge om en broder eller lignende kan være fader til barnet ... Lad os betragte et konkret eksempel på bestemmelse af det samlede faderskabsindeks. Vi har at gøre med et dansk barn (B), hvis alleler på 16 forskellige loci er kendte. De er angivet i kolonne 2 i den store tabel lidt længere nede på siden. Endvidere er moderens (M) og den testede mands (TM) genotyper kendte. De står i kolonne 3 og 4 i tabellen. Genotypefrekvenserne i den danske befolkning er desuden kendte. Der skal udregnes et faderskabsindeks for hvert locus. Lad os se på
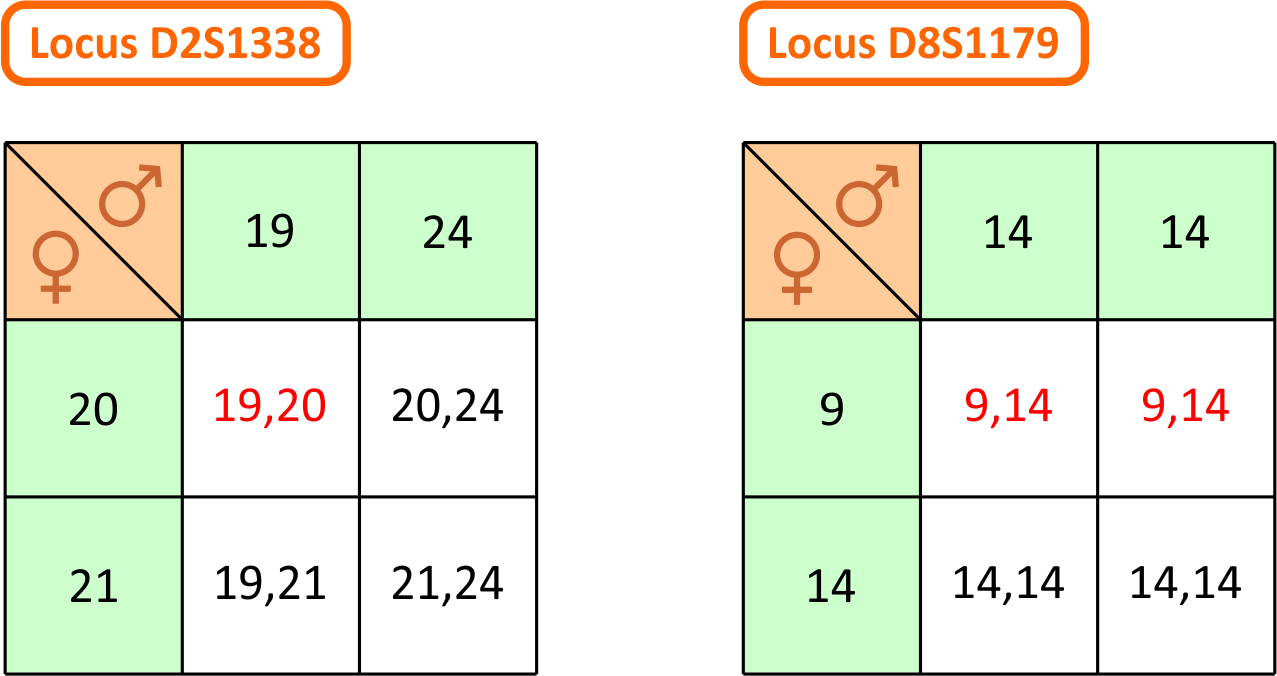
locus D2S1338: Vi ser, at barnet på dette locus har genotypen 19,20, mens moderen og den testede mand har henholdsvis genotype 20,21 og 19,24. Vi kan stille det op i en krydsningstabel: Der er kun én mulighed for at barnet får genotype 19,20, og det er hvis moderen leverer allel 20 og den testede mand leverer allel 19. Da det sker med sandsynlighed 0,50 for hver, er sandsynligheden for at begge indtræffer dermed produktet af sandsynlighederne, dvs. 0,25. Vi har her brugt, at hændelserne er uafhængige. Dermed har vi udregnet tælleren i faderskabsindekset PI for dette locus. For at udregne nævneren, skal vi udskifte
den testede mand med en vilkårlig anden mand. Vi ved stadig, at manden skal levere allel 19. Sandsynligheden for, at han gør det, er lig med allel-frekvensen for allel 19 på locus D2S1338 i den danske befolkning. Hvis vi kalder den for p1, så er sandsynligheden for at moderen leverer allel 20 og faderen allel 19 altså p1/2. Dermed har vi nævneren i PI. Divideres tæller med nævner, fås PI til 5,02, som det ses i tabellen længere nede på siden. Med denne viden er den testede mands odds for
at være den biologiske fader altså forøget med ca. en faktor 5! Bemærk at værdien for p1 fås fra Excel-filen med data fra populationsdatabasen fra afsnit 9 ovenfor!
Situationen på locus D8S1179 er lidt mere kompliceret. Af krydningstabellen til højre på figuren herover ser vi, at for at barnet kan få genotype 9,14 på dette locus, skal moderen levere allel 9, mens det er ligegyldigt hvilken allel den testede mand leverer. Det giver alt i alt en sandsynlighed på 0,5 for tælleren i PI. Når vi går til nævneren er det lidt mere komplekst, for når vi tager en vilkårlig anden mand, så kan det jo godt være, at denne mand kommer med en allel 9! Der er altså to muligheder: Enten leverer moderen allel 9 og manden allel 14 eller også omvendt. Hvis vi betegner allel-frekvenserne for allel 9 og 14 i den danske befolkning med henholdsvis p1 og p2, så er sandsynlighederne for de to muligheder altså henholdvis p1/2 og p2/2. Da de to muligheder indbyrdes udelukker hinanden, kan vi bruge additionsprincippet og lægge sandsynlighederne for hændelserne sammen. Det betyder, at sandsynligheden i nævneren er p1/2 + p2/2, som er det samme som (p1 + p2)/2. Indsætter vi værdierne for allel-frekvenserne for allel 9 og 14 og dividerer op i tælleren, får vi ifølge tabellen en PI på 4,68. Situationen i de øvrige loci beregnes ved lignende overvejelser og kan ses i tabellen herunder. Kolonnerne med overskriften p1 og p2, indeholder allel-frekvenserne for allelerne for barnet - altid med den mindste allel først. De alleller, som er i spil i beregningerne er desuden markeret med grønt.
Skemaets værdier kan du genfinde i Excel-filen. Man får det samlede faderskabsindeks PI ved at multiplicere værdierne for PI på hvert locus. Antagelsen er, at der er uafhængighed mellem de enkelte loci. Ovenfor har vi altså at odds for, at den testede mand er den biologiske fader til barnet, er forøget med en faktor på ca. 900 mio. Som nævnt i afsnit 1 har man på Retsgenetisk Afdeling i Danmark valgt at være meget konservativ og kun angive det som > 10000 for at tage højde for usikkerheder. Nogle gange kan man komme ud for at PI-værdien i et locus er 0, fordi det ikke kan lade sig gøre, at barnet har modtaget en allel fra moderen og en allel fra den testede mand. Det betyder ikke, at man uden videre forkaster hypotesen om, at den testede mand er faderen. Der kan nemlig foregå mutationer. Faktisk tillader man op til to mulige mutationer, før man afviser at den testede mand kan være faderen til barnet. Ifølge Jakob fra Retsgenetisk Afdeling regner man normalt med en mutationsrate (sandsynlighed) på 0,003 på de sædvanlige STR-loci. En eller flere inkonsistenser mellem barnets og den testede mands genotyper, kan dog også kaste en mistanke på, om en broder kan være fader til barnet! I princippet kan man også komme ud for, at den formodede fader ikke er tilgængelig for en DNA-test. I det tilfælde kan man dog også sige noget, såfremt man kan teste personer, som er i familie med nævnte person. Værdien af PI vil da ikke blive så høj som normalt. Jakob nævner også, at man anvender de samme 16 genetiske markører (NGM-Select) til udredning af slægtskabsproblemstillinger. Der kan dog suppleres afhængigt af problemstillingen med undersøgelse af markører på X-kromosomet (Argus-X), Y-kromosomet (Y-filerPlus) og/eller af autosomale SNPs (Single Nucleotide Polymorphisms). I tilfældet med faderskabssager er det ifølge Jakob aftalt med rekvirenten, at man – hvis det er muligt - laver supplerende undersøgelser indtil den samlede IP er mindst 10000:1 FOR faderskab eller 10000:1 IMOD faderskab. Eksempel En kvinde påstår, at en bestemt person er far til hendes barn og forlanger, at han skal betale børnepenge. Manden benægter, og sagen kommer for en civil ret. Der tages DNA-prøver fra barnet (B), moderen (M) og den testede mand (TM). Allelerne, som er bestemt på 16 STR-loci, fremgår af skemaet ovenfor. Der skal beregnes et samlet faderskabsindeks PI (Paternity Index) for DNA-beviset. Alle involverede er etniske danske. Ud fra moderens andre mandlige bekendtskaber vurderes det, at forhånds-odds for, at den testede mand er den biologiske fader til barnet, er 1,5. Benyt Bayes' formel på odds form til at bestemme (de opdaterede) odds for, at den testede mand er den biologiske far til barnet, efter at der tages højde for DNA-beviset. Løsning : Hændelsen H står her for "den testede mand er den biologiske fader til barnet". Som oplyst ovenfor vil Retsgenetisk Afdeling i Danmark - på trods af det meget høje faderskabsindeks (likelihood-kvotient) bestemt ovenfor (904968523) - nedsætte tallet til 10000, for at tage højde for usikkerheder og være meget på den sikre side. Det vil nedsætte betydningen af DNA-beviset en del og lade forhåndsodds få større betydning. I dette tilfælde fås dermed:
som er de opdaterede odds for at den testede mand er fader til barnet, efter at der er taget højde for DNA-beviset. Odds er så høje, at dommen sandsynligvis vil være, at den testede mand er fader til barnet.
12. Links
13. Litteratur
Opdateret 04.04.22
|
|
|





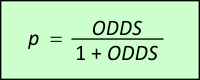
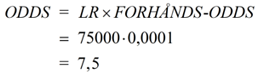
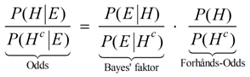




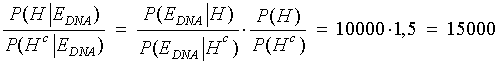


{kind=link}